Пожалуйста, войдите в свой аккаунт, или зарегистрируйтесь и добавьте свои Telegram-каналы и бизнес-сообщества ВКонтакте в личном кабинете.
Для бесплатной генерации поста использовался промт/статья:
<b>В Nvidia скрестили трансформеры с Mamba-2 и выпустили Nemotron-H</b>
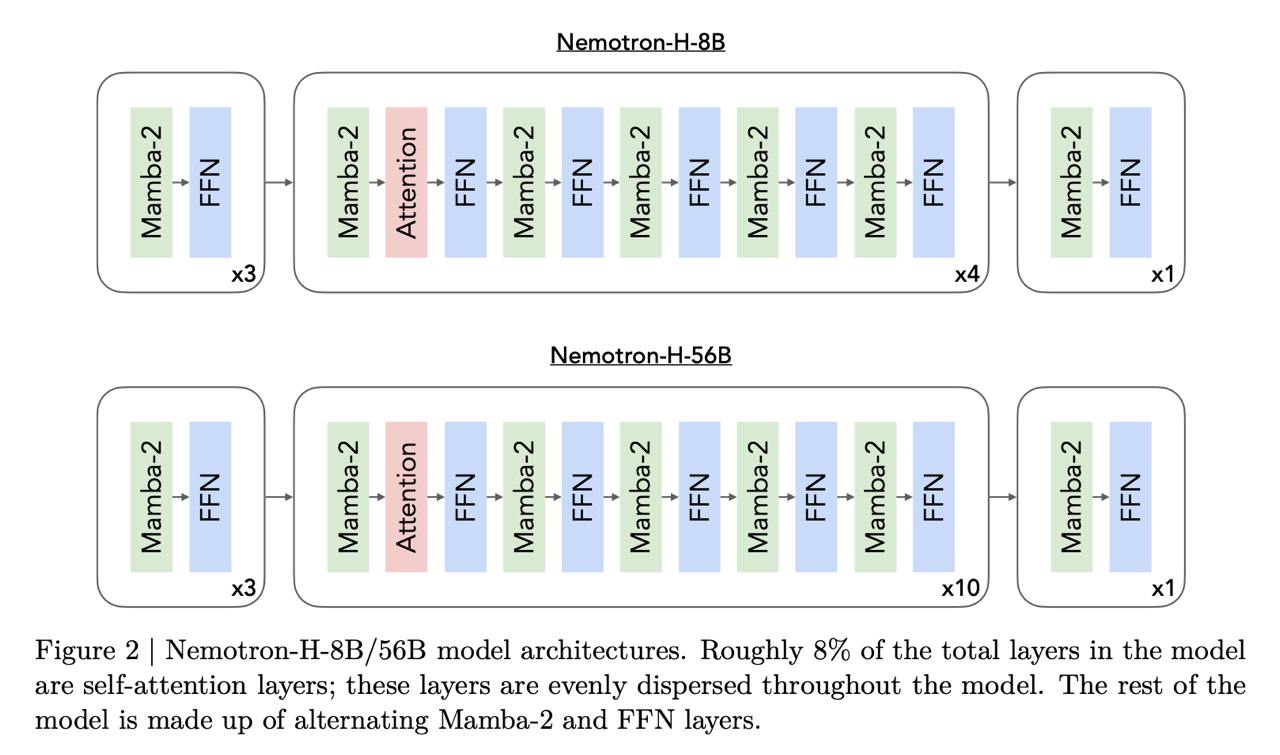
Исследователи взяли обычный трансформер, но большинство слоев внимания заменили на слои Mamba-2. Mamba – это модель из семейства State space models, это такой умный вариант<b> </b>LSTM (<a href="https://t.me/data_secrets/5433">вот тут</a> наш понятный разбор того, как SSM работают).
Для модели 56B осталось только 10 слоев селф-аттеншена, а для модели 8B – 4 слоя. С точки зрения экономии ресурсов и ускорения это очень круто, потому что <b>в слоях mamba память константная</b>. То есть вычисления вообще не зависят от длины контекста (в отличие от внимания, которое масштабируется квадратично).
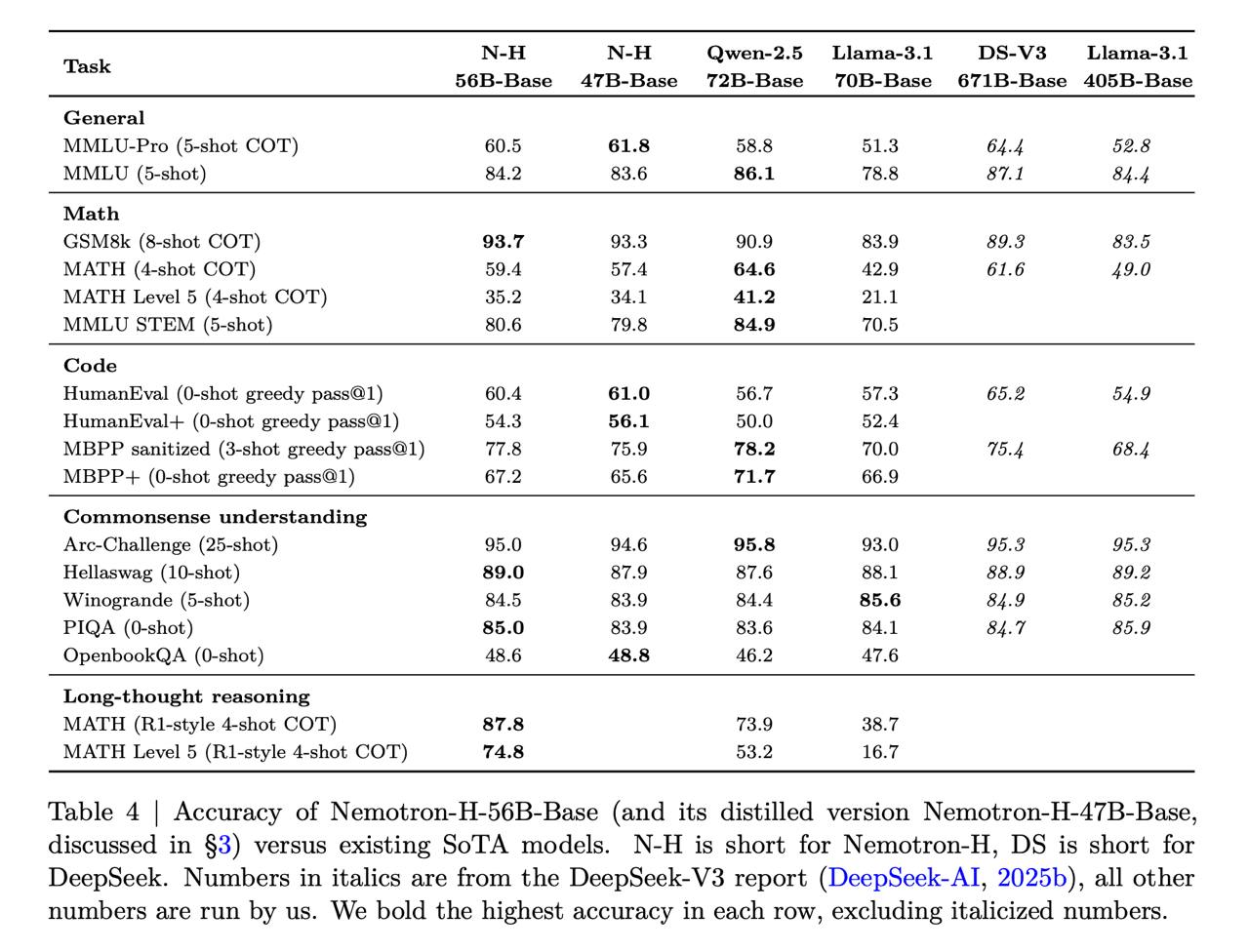
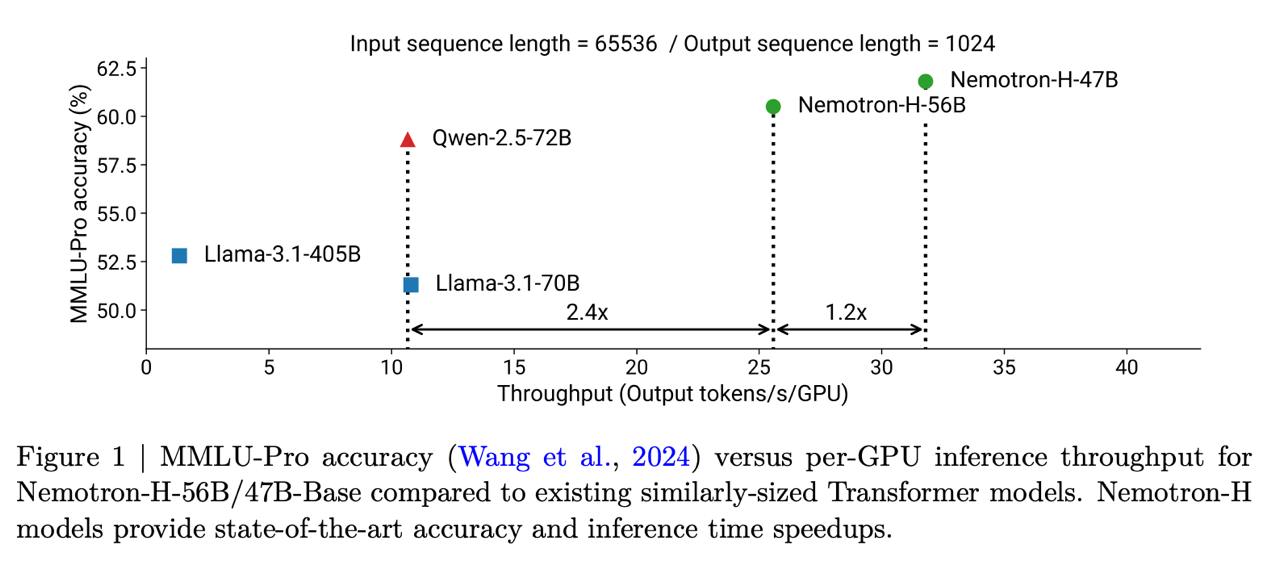
Интуитивно кажется, что тогда должно страдать качество. Но нет: <b>результаты сопоставимы с чистыми трансформерами схожих размеров</b>. Например, Nemotron-H-56B примерно на уровне с Llama-3.1-70B и Qwen-2.5-72B. При этом летает все в 2-3 раза быстрее.
Интересно, появится ли моделька на арене (<a href="https://huggingface.co/collections/nvidia/nemotron-h-67fd3d7ca332cdf1eb5a24bb">веса здесь</a>)
arxiv.org/pdf/2504.03624