Пожалуйста, войдите в свой аккаунт, или зарегистрируйтесь и добавьте свои Telegram-каналы и бизнес-сообщества ВКонтакте в личном кабинете.
Для бесплатной генерации поста использовался промт/статья:
<b>Nvidia не перестает радовать: совместно с Корнеллским Университетом они предложили Eso-LM – новую архитектуру, сочетающую в себе авторегрессию и диффузию</b>
Буквально в прошлом посте мы написали, что, возможно, за диффузионными текстовыми моделями будущее, – и сразу же наткнулись на только что выпущенную статью Nvidia про новую архитектуру, основанную на этой идее.
Кратко разбираем:
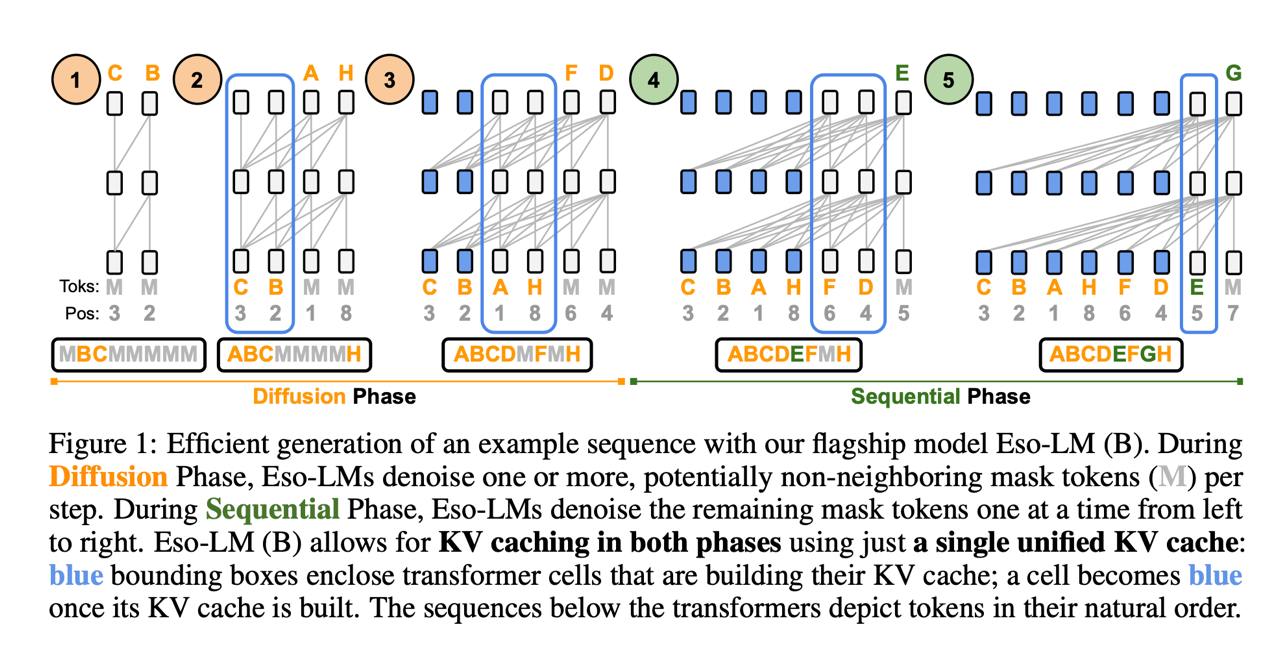
<emoji id="5417934298525230493">➖</emoji> Авторегрессивные модели (трансформеры) генерируют токены слева направо, а диффузионные – постепенно размаскировывают последовательность в любом порядке. Это значит, что диффузию можно параллелить на инференсе, восстанавливая по нескольку токенов за раз, а трансформеры – нет. В Eso-LM авторы попытались <b>соединить два подхода, чтобы качество было, как у авторегрессии, а скорость – как у диффузии</b>.
<emoji id="5417934298525230493">➖</emoji> Тут у нас две фазы инференса. Сначала диффузионная: модель параллельно восстанавливает большинство токенов. Затем авторегрессивная: оставшиеся замаскированные позиции достраиваются последовательно слева направо.
<emoji id="5417934298525230493">➖</emoji> При этом в диффузионной фазе токены восстанавливаются по заранее заданному расписанию, которое определяется перестановкой индексов σ – эта схема определяет, какие позиции размаскируются на каждом шаге. Благодаря тому, что порядок фиксирован, для уже восстановленных токенов можно накапливать KV-кеш и быстро переиспользовать его в автоконтекстной фазе. Это называется <b>казуальным вниманием</b>.
В итоге у нас: качество – трансформеров, а скорость – диффузии. На тестах Eso-LM демонстрирует perplexity около 25.97 против 22.83 у обычного авторегрессивного трансформера.
<a href="https://arxiv.org/pdf/2506.01928">Статья полностью</a>