Пожалуйста, войдите в свой аккаунт, или зарегистрируйтесь и добавьте свои Telegram-каналы и бизнес-сообщества ВКонтакте в личном кабинете.
Для бесплатной генерации поста использовался промт/статья:
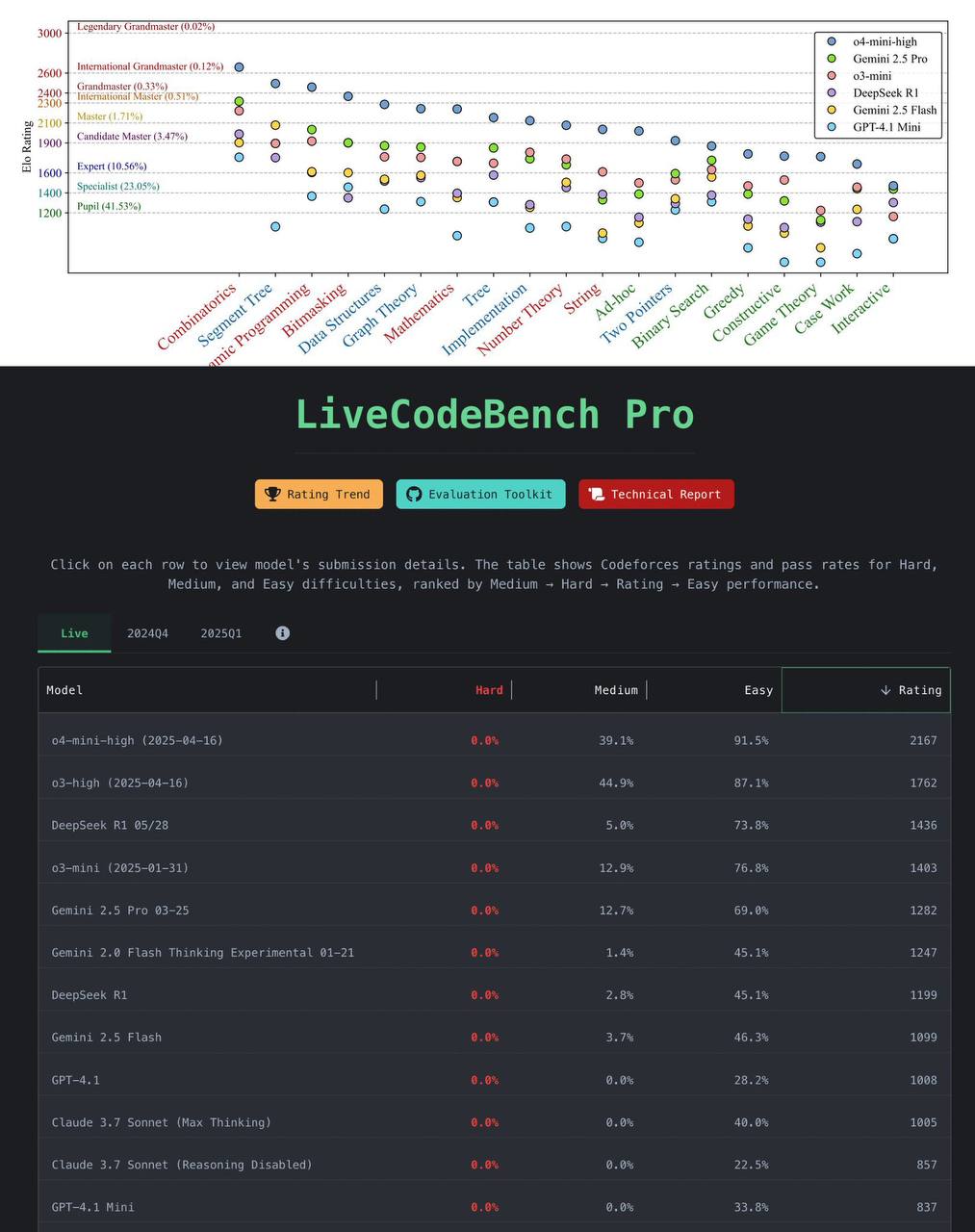
<b>Там вышел новый бенчмарк по программированию – модели выбивают на нем 0%</b> <emoji id="5850515368694517361">😐</emoji>
LiveCodeBench Pro состоит из самых свежих и самых сложных задач по программированию с Codeforces, ICPC, and IOI (International Olympiad in Informatics). Размечали их сами победители и призеры олимпиад.
Итог: даже лучшая модель o4-mini-high достигает рейтинга около 2100. Это очень далеко от гроссмейстеров-людей (~2700).
При этом модели способны решать только простые и некоторые средние задачи. На по-настоящему сложных абсолютно все LM – чистый ноль.
У них неплохо получается решать задачи на комбинаторику и динамическое программирование. Но в теории игр и работе с угловыми случаями они на уровне среднего эксперта или даже ученика.
И вот что еще интересно: у людей ошибки обычно в реализации, а не в алгоритме. То есть бытовая невнимательность или синтаксис. У моделей же провалы чаще на уровне самой идеи.
Олимпиадников пока не заменяем, получается
arxiv.org/pdf/2506.11928