Пожалуйста, войдите в свой аккаунт, или зарегистрируйтесь и добавьте свои Telegram-каналы и бизнес-сообщества ВКонтакте в личном кабинете.
Для бесплатной генерации поста использовался промт/статья:
<a href="https://arxiv.org/pdf/2504.17192"><b>Paper2Code</b></a><b>: исследователи из корейского технологического института сделали мульти-агентный фрейморк для автоматической генерации кода по статьям</b>
Боль каждого рисерчера – это статьи, к которым нет кода. Чтобы воспроизвести результат, нужно потратить пол жизни, и то – успех не гарантирован. А код авторы публикуют не так уж и часто. На примере NeurIPS, ICML и ICLR 2024: <b>только 21.2% принятых работ имеют открытые репы</b>.
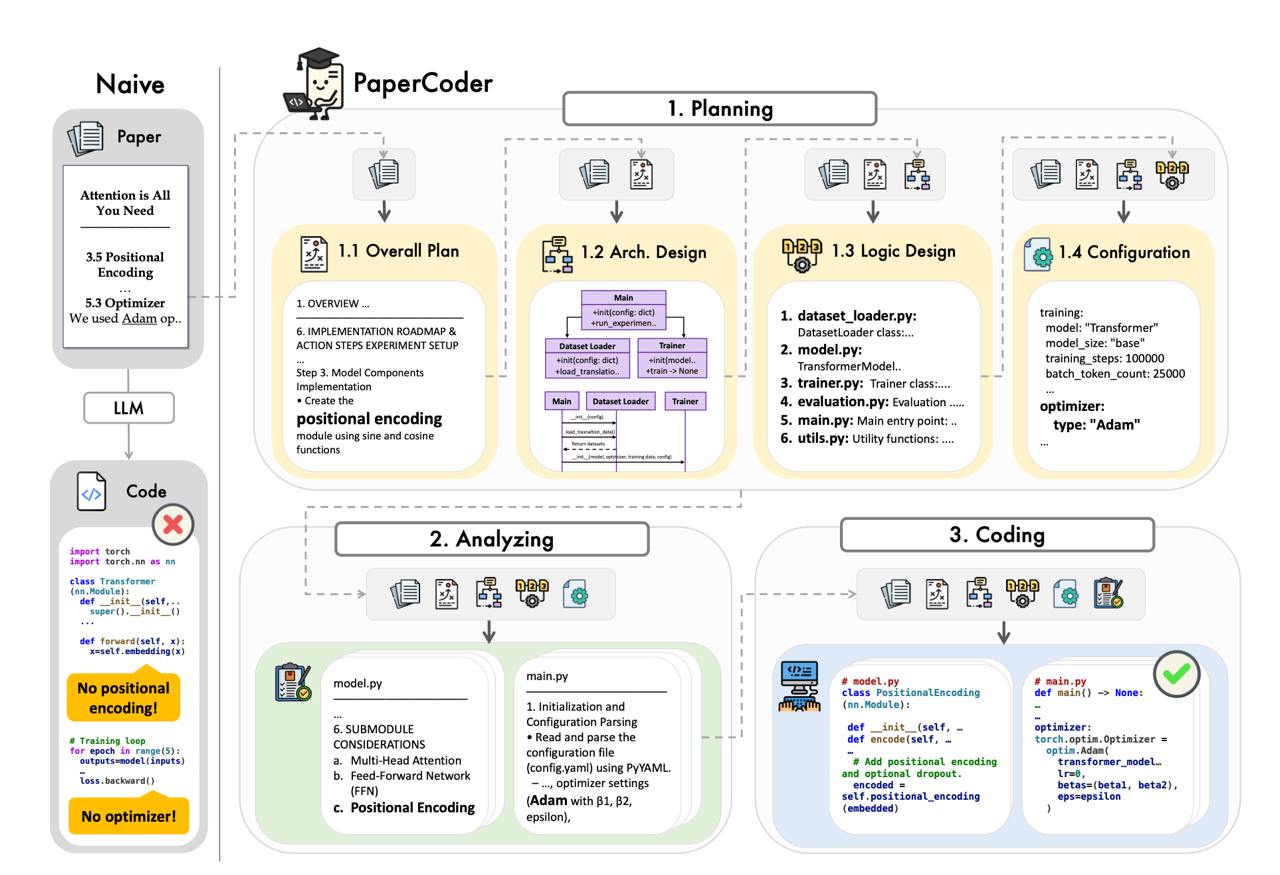
Здесь авторы предлагают PaperCoder. Это мульти-агентная система, в которой процесс генерации репозитория разбит на три этапа:
1. <b>Планирование</b>. Составляется конспект статьи, UML-диаграммы классов + список файлов. Тут же создается config.yaml с гиперпараметрами и выстраивается план последовательности генерации.
2. <b>Анализ</b>. Здесь для каждого файла из составленного списка формируется file-level analysis — подробное описание целей, входов/выходов, взаимодействий и каких-то специфичных требований, если есть.
3. <b>Ну и сама генерация</b> на основании статьи, фазы планирования и анализа. Бонусом из первых двух пунктов получаем супер-подробную доку.
На каждом шаге работает отдельный агент. Это, по идее, могут быть разные LLM, но здесь по умолчанию на всех шагах стоит <b>o3-mini-high</b> (кроме валидации, там GPT-4o).
Тестировали на работах с тех же ICML/NeurIPS/ICLR 2024. Процент полностью успешной репликации – около 44% против 10-15 у базовых агентов. Если анализировать вручную, то в среднем для успешного запуска нужно менять всего 0.48 % строк. А еще PaperCoder давали потрогать исследователям, и в 85% случаев те сказали, что это лучше, чем писать с нуля, даже если нужно что-то дебажить.
<b>Ирония только в том, что к статье Paper2Code... не выложили код</b>. Но, вроде, обещают "скоро"