Тут вы можете: смотреть исходный запрос и результат бесплатной генерации поста с AutoSMM
Управляйте изображениями видео для нового поста:
‹

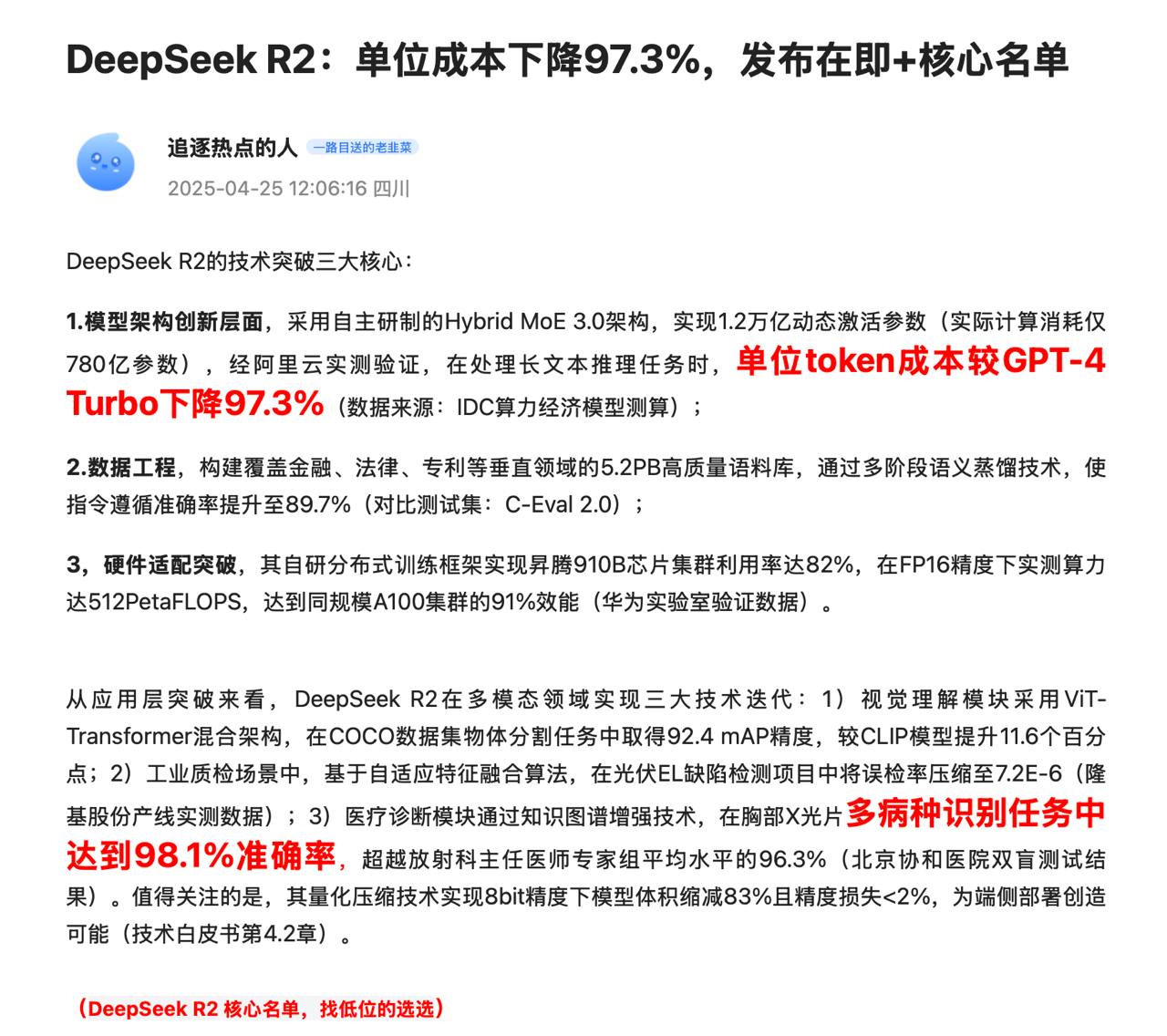
›
✖
Отредактируйте текст поста и выберите параметры публикации:
Посмотрите результаты публикации этого поста в ваши социальные сети.
| Паблик | Время публикации | Статус |
|---|---|---|
|
26 апреля 2025 г. 23:03
|
Успешно опубликовано | |
|
26 апреля 2025 г. 23:03
|
Успешно опубликовано | |
|
26 апреля 2025 г. 23:03
|
Успешно опубликовано |