Пожалуйста, войдите в свой аккаунт, или зарегистрируйтесь и добавьте свои Telegram-каналы и бизнес-сообщества ВКонтакте в личном кабинете.
Для бесплатной генерации поста использовался промт/статья:
<emoji id="5373066810998410226">⚡️</emoji> <b>Вышел Qwen-3, встречаем новую открытую соту</b>
Выпустили 2 MoE и 6 dense моделей в весах на любой вкус, 0.6В до 235B. Разбираем.
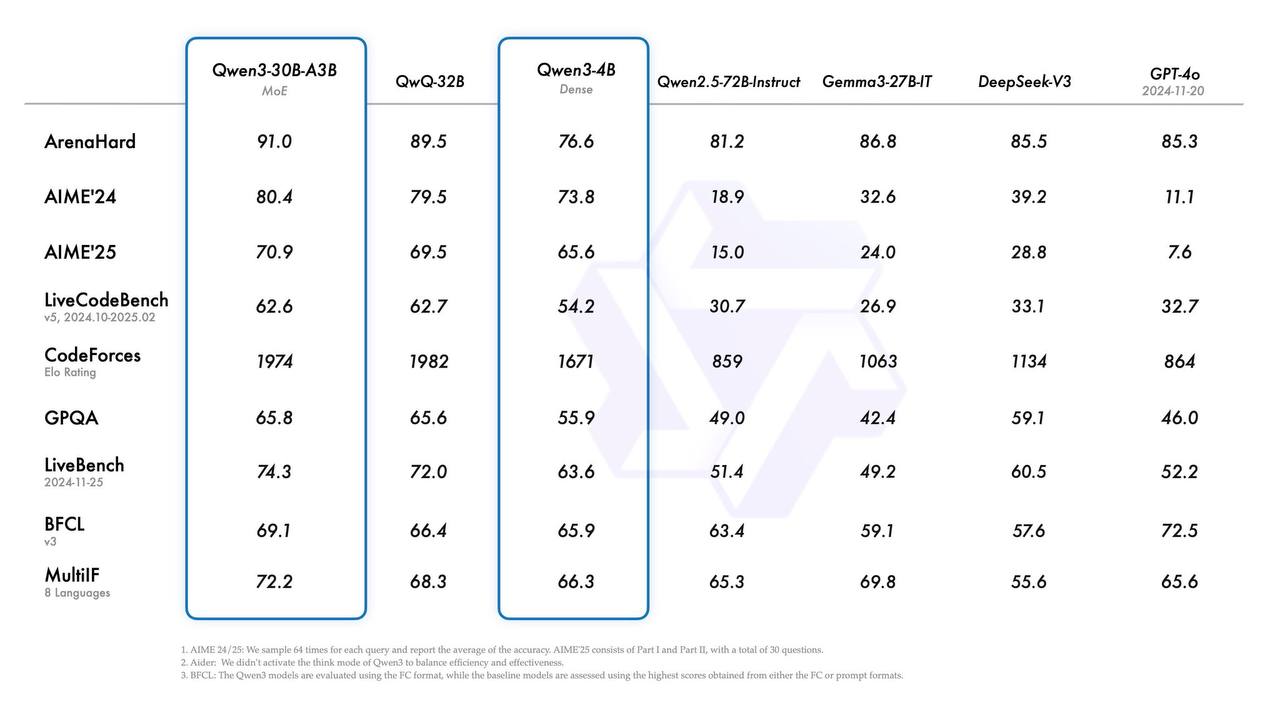
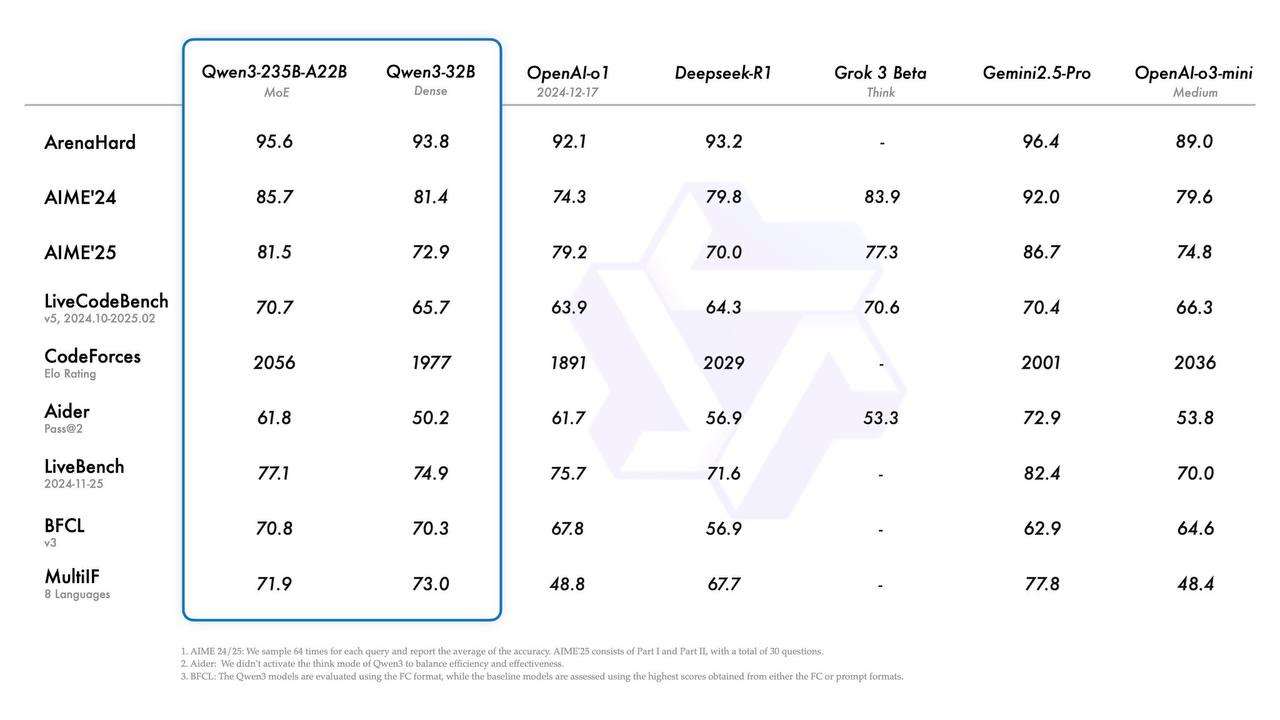
Самая большая модель <b>на уровне со всеми звездами</b> – Gemini 2.5 Pro, Grok-3, o1, R1. И это MoE всего с 22В активных параметров. На 30В MoE модель тоже крутая получилась: на бенчах видно, что она лучше предыдущего ризонера QwQ-32B (при этом активных параметров у нее всего 3В, то есть в 10 раз меньше).
Что еще чтоит знать:
1. Это <b>полу-ризонеры</b>, как Sonnet 3.7 или Gemini 2.5 Pro. То есть модель будет «думать», если задать мод think, и не думать, если задать Non-Thinking. Бюджет рассуждений тоже можно контролировать.
2. Модели мультиязычные (русский тоже есть), но не мультимодальные. Довольствуемся тем, что есть.
3. Улучшены агентные способности на уровне поиска в браузере, использования интерпретатора и др. Что особенно приятно – добавили поддержку MCP.
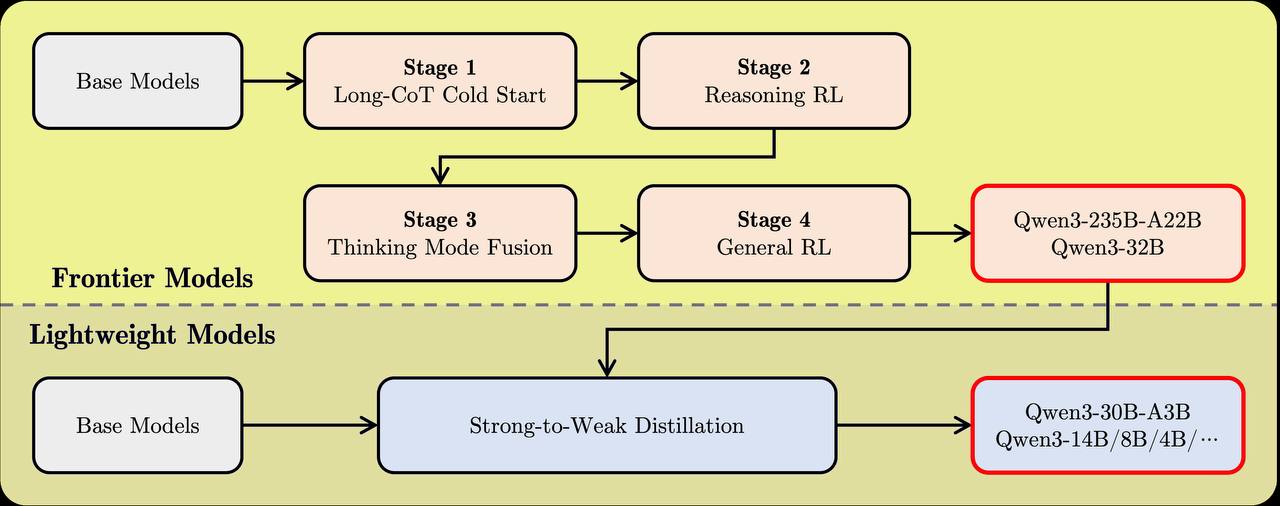
4. <b>Претрейнинг был в три этапа</b>: сначала на 30 триллионах токенов с контекстом 4К, затем отдельно на сложных научных текстах (5Т), потом на длинных контекстах до 32К токенов.
5. <b>Пост-трейнинг</b>: файн-тюнинг на CoT + несколько стадий RL. Интересно, что мелкие модели до 30В обучали дистилляцией из крупных.
В общем, пробуем и наслаждаемся <a href="https://chat.qwen.ai/">здесь</a>
<a href="https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f"><b>Веса</b></a><b> | </b><a href="https://qwenlm.github.io/blog/qwen3/"><b>Блогпост</b></a><b> | </b><a href="https://github.com/QwenLM/Qwen3"><b>Гитхаб</b></a>